
Tornado进阶
阅读 (213042)一、Application
-
settings
前面的学习中,我们在创建tornado.web.Application的对象时,传入了第一个参数——路由映射列表。实际上Application类的构造函数还接收很多关于tornado web应用的配置参数
-
参数
debug设置
tornado是否工作在调试模式,默认为False即工作在生产模式。当设置debug=True 后,tornado会工作在调试/开发模式
tornado为方便我们开发而提供了几种特性
-
自动重启:tornado应用会监控我们的源代码文件,当有改动保存后便会重启程序,这可以减少我们手动重启程序的次数。需要注意的是,一旦我们保存的更改有错误,自动重启会导致程序报错而退出,从而需要我们保存修正错误后手动启动程序。这一特性也可单独通过autoreload=True设置
-
取消缓存编译的模板:可以单独通过compiled_template_cache=False来设置
-
取消缓存静态文件hash值:可以单独通过static_hash_cache=False来设置;
-
提供追踪信息:当RequestHandler或者其子类抛出一个异常而未被捕获后,会生成一个包含追踪信息的页面,可以单独通过serve_traceback=True来设置
-
-
使用debug参数的方法
import tornado.web app = tornado.web.Application([], debug=True) -
使用autoreload参数的方法
app = tornado.web.Application([ (r"/", IndexHandler), ],autoreload=True) -
路由映射
先前我们在构建路由映射列表的时候,使用的是二元元组,如:
[(r"/", IndexHandler),]对于这个映射列表中的路由,实际上还可以传入多个信息,如:
from tornado.web import url [ (r"/", Indexhandler), (r"/cpp/", ITHandler, {"subject":"c++"}), url(r"/python/", ITHandler, {"subject":"python"}, name="python_url") ]url方法:指定URL和处理程序之间的映射。
对于路由中的字典,会传入到对应的RequestHandler的initialize()方法中
from tornado.web import RequestHandler class ITHandler(RequestHandler): def initialize(self, subject): self.subject = subject def get(self): self.write(self.subject)对于路由中的name字段,注意此时不能再使用元组,而应使用tornado.web.url来构建。name是给该路由起一个名字,可以通过调用RequestHandler.reverse_url(name)来获取该名子对应的url
import tornado.web import tornado.ioloop import tornado.httpserver import tornado.options from tornado.options import options, define from tornado.web import url, RequestHandler define("port", default=8000, type=int, help="run server on the given port.") class IndexHandler(RequestHandler): def get(self): python_url = self.reverse_url("python_url") self.write('<a href="%s">python学科</a>' % python_url) class ITHandler(RequestHandler): def initialize(self, subject): self.subject = subject def get(self): self.write(self.subject) if __name__ == "__main__": tornado.options.parse_command_line() app = tornado.web.Application([ (r"/", Indexhandler), (r"/cpp", ITHandler, {"subject":"c++"}), url(r"/python", ITHandler, {"subject":"python"}, name="python_url") ], debug = True) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(options.port) tornado.ioloop.IOLoop.current().start() -
重写 RequestHandler 的方法函数
对于一个请求的处理过程代码调用次序如下
- 程序为每一个请求创建一个 RequestHandler 对象
- 程序调用
initialize()函数,这个函数的参数是Application配置中的关键字参数定义。(initialize方法是 Tornado 1.1 中新添加的,旧版本中你需要重写__init__以达到同样的目的)initialize方法一般只是把传入的参数存到成员变量中,而不会产生一些输出或者调用像send_error之类的方法 - 程序调用
prepare()。无论使用了哪种 HTTP 方法,prepare都会被调用到,因此这个方法通常会被定义在一个基类中,然后在子类中重用。prepare可以产生输出信息。如果它调用了finish(或send_error` 等函数),那么整个处理流程就此结束 - 程序调用某个 HTTP 方法:例如
get()、post()、put()等。如果 URL 的正则表达式模式中有分组匹配,那么相关匹配会作为参数传入方法。
重写 initialize() 函数(会在创建RequestHandler对象后调用)
class ProfileHandler(tornado.web.RequestHandler): def initialize(self,database): self.database = database def get(self): self.write("result:" + self.database) application = tornado.web.Application([ (r"/init", ProfileHandler, dict(database="database")) ])
二、请求
下面主要讲解tornado.web.RequestHandler
-
利用HTTP协议向服务器传参有几种途径
- 查询字符串(query string),形如key1=value1&key2=value2
- 请求体(body)中发送的数据,比如表单数据、json、xml
- 提取uri的特定部分,如/blogs/2019/09/0001,可以在服务器端的路由中用正则表达式截取
- 在http报文的头(header)中增加自定义字段,如X-XSRFToken=xxx
-
tornado中提供了以下方法来获取请求的信息
-
获取查询字符串参数
-
get_query_argument(name, default=_ARG_DEFAULT, strip=True)注意:从请求的查询字符串中返回指定参数name的值,如果出现多个同名参数,则返回最后一个的值
default为设值未传name参数时返回的默认值,如若default也未设置,则会抛出tornado.web.MissingArgumentError异常
strip表示是否过滤掉左右两边的空白字符,默认为过滤
-
get_query_arguments(name, strip=True)
从请求的查询字符串中返回指定参数name的值,注意返回的是list列表(即使对应name参数只有一个值)。若未找到name参数,则返回空列表[]
strip同前,不再赘述
-
-
获取请求体参数
-
get_body_argument(name, default=_ARG_DEFAULT, strip=True)从请求体中返回指定参数name的值,如果出现多个同名参数,则返回最后一个的值。
default与strip同前,不再赘述
-
get_body_arguments(name, strip=True)
从请求体中返回指定参数name的值,注意返回的是list列表(即使对应name参数只有一个值)。若未找到name参数,则返回空列表[]
strip同前,不再赘述
说明:对于请求体中的数据要求为字符串,且格式为表单编码格式(与url中的请求字符串格式相同),即key1=value1&key2=value2,HTTP报文头Header中的"Content-Type"为application/x-www-form-urlencoded 或 multipart/form-data。对于请求体数据为json或xml的,无法通过这两个方法获取。
-
-
前两类方法的整合
-
get_argument(name, default=_ARG_DEFAULT, strip=True)
从请求体和查询字符串中返回指定参数name的值,如果出现多个同名参数,则返回最后一个的值
default与strip同前,不再赘述
-
get_arguments(name, strip=True)
从请求体和查询字符串中返回指定参数name的值,注意返回的是list列表(即使对应name参数只有一个值)。若未找到name参数,则返回空列表[]
strip同前,不再赘述
说明:对于请求体中数据的要求同前 这两个方法最常用
-
-
-
使用
import tornado.web import tornado.ioloop import tornado.httpserver import tornado.options from tornado.options import options, define from tornado.web import RequestHandler, MissingArgumentError define("port", default=8000, type=int, help="run server on the given port.") class IndexHandler(RequestHandler): def post(self): query_arg = self.get_query_argument("a") query_args = self.get_query_arguments("a") body_arg = self.get_body_argument("a") body_args = self.get_body_arguments("a", strip=False) arg = self.get_argument("a") args = self.get_arguments("a") default_arg = self.get_argument("b", "itcast") default_args = self.get_arguments("b") try: missing_arg = self.get_argument("c") except MissingArgumentError as e: missing_arg = "We catched the MissingArgumentError!" print e missing_args = self.get_arguments("c") rep = "query_arg:%s<br/>" % query_arg rep += "query_args:%s<br/>" % query_args rep += "body_arg:%s<br/>" % body_arg rep += "body_args:%s<br/>" % body_args rep += "arg:%s<br/>" % arg rep += "args:%s<br/>" % args rep += "default_arg:%s<br/>" % default_arg rep += "default_args:%s<br/>" % default_args rep += "missing_arg:%s<br/>" % missing_arg rep += "missing_args:%s<br/>" % missing_args self.write(rep) if __name__ == "__main__": tornado.options.parse_command_line() app = tornado.web.Application([ (r"/", IndexHandler), ]) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(options.port) tornado.ioloop.IOLoop.current().start()
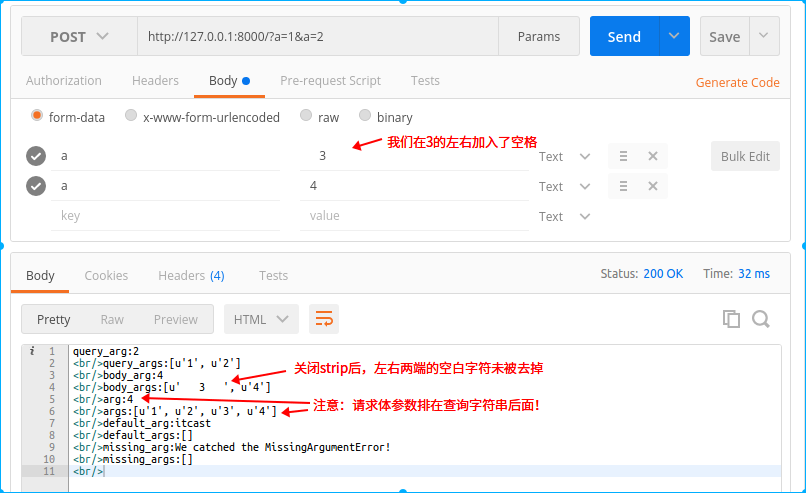
-
RequestHandler.request属性
说明:RequestHandler.request 对象存储了关于请求的相关信息
格式:self.request.属性名
-
method HTTP的请求方式,如GET或POST
-
host 被请求的主机名
-
uri 请求的完整资源标示,包括路径和查询字符串
-
path 请求的路径部分
-
query 请求的查询字符串部分
-
version 使用的HTTP版本
-
headers 请求的协议头,是类字典型的对象,支持关键字索引的方式获取特定协议头信息,例如:request.headers[“Content-Type”]
-
body 请求体数据
-
remote_ip 客户端的IP地址
-
files 用户上传的文件,为字典类型,型如:
{ "form_filename1":[<tornado.httputil.HTTPFile>, <tornado.httputil.HTTPFile>], "form_filename2":[<tornado.httputil.HTTPFile>,], ... }tornado.httputil.HTTPFile是接收到的文件对象三个属性:
filename 文件的实际名字,与form_filename1不同,字典中的键名代表的是表单对应项的名字
body 文件的数据实体
content_type 文件的类型。 这三个对象属性可以像字典一样支持关键字索引,如request.files[“form_filename1”][0][“body”]
-
-
文件上传 (模板中讲解)
-
正则提取uri
-
说明
tornado中对于路由映射也支持正则提取uri,提取出来的参数会作为RequestHandler中对应请求方式的成员方法参数。若在正则表达式中定义了名字,则参数按名传递;若未定义名字,则参数按顺序传递。提取出来的参数会作为对应请求方式的成员方法的参数
-
示例
import tornado.web import tornado.ioloop import tornado.httpserver import tornado.options from tornado.options import options, define from tornado.web import RequestHandler define("port", default=8000, type=int, help="run server on the given port.") class IndexHandler(RequestHandler): def get(self): self.write("hello lucky") class SubjectCityHandler(RequestHandler): def get(self, subject, city): self.write(("Subject: %s<br/>City: %s" % (subject, city))) class SubjectDateHandler(RequestHandler): def get(self, date, subject): self.write(("Date: %s<br/>Subject: %s" % (date, subject))) if __name__ == "__main__": tornado.options.parse_command_line() app = tornado.web.Application([ (r"/", IndexHandler), (r"/sub-city/(.+)/([a-z]+)", SubjectCityHandler), # 无名方式 (r"/sub-date/(?P<subject>.+)/(?P<date>\d+)", SubjectDateHandler), # 命名方式 ]) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(options.port) tornado.ioloop.IOLoop.current().start()建议:提取多个值时最好用命名方式
三、响应
-
write(chunk)
-
将chunk数据写到输出缓冲区
class IndexHandler(RequestHandler): def get(self): self.write("hello lucky!")多次写入
class IndexHandler(RequestHandler): def get(self): self.write("lucky is a good man!") self.write("lucky is a good handsome man!") self.write("lucky is a lucky man!")注意:write方法是写到缓冲区的,我们可以像写文件一样多次使用write方法不断追加响应内容,最终所有写到缓冲区的内容一起作为本次请求的响应输出
-
写入json数据
json.dumps
import json class IndexHandler(RequestHandler): def get(self): stu = { "name": "lucky", "age": 18, "sex": 'man', } stu_json = json.dumps(stu) self.write(stu_json)注意:实际上,我们可以不用自己手动去做json序列化,当write方法检测到我们传入的chunk参数是字典类型后,会自动帮我们转换为json字符串
write自动转换
class IndexHandler(RequestHandler): def get(self): stu = { "name": "lucky", "age": 18, "sex": 'man', } self.write(stu)区别
- 对比一下两种方式的响应头header中
Content-Type字段,自己手动序列化时为Content-Type:text/html; charset=UTF-8,而采用write方法时为Content-Type:application/json; charset=UTF-8
- 对比一下两种方式的响应头header中
-
write方法除了帮我们将字典转换为json字符串之外,还帮我们将
Content-Type设置为application/json; charset=UTF-8 -
关于Content-Type几种值的区别及用法
Content-Type 的值类型:
- application/json:消息主体是序列化后的 JSON 字符串
- application/x-www-form-urlencoded:数据被编码为名称/值对。这是标准的编码格式
- multipart/form-data: 需要在表单中进行文件上传时,就需要使用该格式。常见的媒体格式是上传文件之时使用的
- text/plain:数据以纯文本形式(text/json/xml/html)进行编码,其中不含任何控件或格式字符
application/json 和 application/x-www-form-urlencoded的区别
-
application/json
作用: 告诉服务器请求的主题内容是json格式的字符串,服务器端会对json字符串进行解析
好处: 前端人员不需要关心数据结构的复杂度,只要是标准的json格式就能提交成功
-
application/x-www-form-urlencoded:是Jquery的Ajax请求默认方式
作用:在请求发送过程中会对数据进行序列化处理,以键值对形式?key1=value1&key2=value2的方式发送到服务器
好处: 所有浏览器都支持
application/x-www-form-urlencoded:信息数据被编码为名称/值对,这是标准且默认的编码格式
- 当action为get时候,客户端把form数据转换成一个字串append到url后面,用’?'分割
- 当action为post时候,浏览器把form数据封装到http body中,然后发送到server。(可以取消post请求的预检请求)
总结:
如果响应类型为 application/json 那么服务器会自动解析 那么到前端的时候就不需要再次解析 直接使用就可以 就和Django和flask中的 JsonHttpresponse和jsonify的作用一样
-
-
设置响应头 set_header(name, value)
说明:利用set_header(name, value)方法,可以手动设置一个名为name、值为value的响应头header字段
-
用set_header方法来实现write设置响应头
import json class IndexHandler(RequestHandler): def get(self): stu = { "name": "lucky", "age": 18, "sex": 'man', } stu_json = json.dumps(stu) self.write(stu_json) self.set_header("Content-Type", "application/json; charset=UTF-8")
-
-
set_default_headers()
说明:该方法会在进入HTTP处理方法前先被调用,可以重写此方法来预先设置默认的headers
注意:在HTTP处理方法中使用set_header()方法会覆盖掉在set_default_headers()方法中设置的同名header
class IndexHandler(RequestHandler): def set_default_headers(self): print("执行了set_default_headers()") # 设置get与post方式的默认响应体格式为json self.set_header("Content-Type", "application/json; charset=UTF-8") # 设置一个名为lucky、值为is a good man的header self.set_header("lucky", "is a good man") def get(self): print("执行了get()") stu = { "name": "lucky", "age": 18, "sex": 'man', } stu_json = json.dumps(stu) self.write(stu_json) self.set_header("lucky", "is a handsome man") # 注意此处重写了header中的lucky字段 def post(self): print("执行了post()") stu = { "name": "lucky", "age": 18, "sex": 'man', } stu_json = json.dumps(stu) self.write(stu_json)终端中打印出的执行

get请求方式的响应header

post请求方式的响应header

-
set_status(status_code, reason=None)
说明:为响应设置状态码
参数说明
- status_code int类型,状态码,若reason为None,则状态码必须为下表中的
- reason string类型,描述状态码的词组,若为None,则会被自动填充标准HTTP状态码
HTTP协议常用标准状态码含义
状态码 含义 备注 200 请求已完成 2XX状态码均为正常状态码返回。 300 多种选择 服务器根据请求可执行多种操作。服务器可根据请求者 (User agent) 来选择一项操作,或提供操作列表供请求者选择。 301 永久移动 请求的网页已被永久移动到新位置。服务器返回此响应(作为对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。您应使用此代码通知 Googlebot 某个网页或网站已被永久移动到新位置。 302 临时移动 服务器目前正从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。此代码与响应 GET 和 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置。 303 查看其他位置 当请求者应对不同的位置进行单独的 GET 请求以检索响应时,服务器会返回此代码。对于除 HEAD 请求之外的所有请求,服务器会自动转到其他位置。 304 未修改 自从上次请求后,请求的网页未被修改过。服务器返回此响应时,不会返回网页内容。 305 使用代理 请求者只能使用代理访问请求的网页。如果服务器返回此响应,那么,服务器还会指明请求者应当使用的代理。 400 错误请求 服务器不理解请求的语法。 401 未授权 请求要求进行身份验证。登录后,服务器可能会对页面返回此响应。 403 已禁止 服务器拒绝请求。 404 未找到 服务器找不到请求的网页。例如,如果请求是针对服务器上不存在的网页进行的,那么,服务器通常会返回此代码。 405 方法禁用 禁用请求中所指定的方法。 406 不接受 无法使用请求的内容特性来响应请求的网页。 407 需要代理授权 此状态代码与401(未授权)类似,但却指定了请求者应当使用代理进行授权。如果服务器返回此响应,那么,服务器还会指明请求者应当使用的代理。 408 请求超时 服务器等候请求时超时。 409 冲突 服务器在完成请求时发生冲突。服务器的响应必须包含有关响应中所发生的冲突的信息。服务器在响应与前一个请求相冲突的PUT请求时可能会返回此代码,同时会提供两个请求的差异列表。 411 需要有效长度 服务器不会接受包含无效内容长度标头字段的请求。 412 未满足前提条件 服务器未满足请求者在请求中设置的其中一个前提条件。 413 请求实体过大 服务器无法处理请求,因为请求实体过大,已超出服务器的处理能力。 414 请求的URI过长 请求的URI(通常为网址)过长,服务器无法进行处理。 415 不支持的媒体类型 请求的格式不受请求页面的支持。 416 请求范围不符合要求 如果请求是针对网页的无效范围进行的,那么,服务器会返回此状态代码。 417 未满足期望值 服务器未满足期望请求标头字段的要求。 499 客户端断开连接 因服务端处理时间过长,客户端关闭了连接。 500 服务器内部错误 服务器遇到错误,无法完成请求。 501 尚未实施 服务器不具备完成请求的功能。例如,当服务器无法识别请求方法时,服务器可能会返回此代码。 502 错误网关 服务器作为网关或代理,从上游服务器收到了无效的响应。 503 服务不可用 目前无法使用服务器(由于超载或进行停机维护)。通常,这只是一种暂时的状态。 504 网关超时 服务器作为网关或代理,未及时从上游服务器接收请求。 505 HTTP版本不受支持 服务器不支持请求中所使用的HTTP协议版本。 示例
class Err404Handler(RequestHandler): """对应/err/404""" def get(self): self.write("hello Lucky") self.set_status(404) # 标准状态码,不用设置reason class Err210Handler(RequestHandler): """对应/err/210""" def get(self): self.write("hello lucky") self.set_status(210, "lucky error") # 非标准状态码,设置了reason class Err211Handler(RequestHandler): """对应/err/211""" def get(self): self.write("hello lucky") self.set_status(211) # 非标准状态码,未设置reason,错误请求结果



-
redirect(url)
说明:重定向 服务器直接跳转
示例
class IndexHandler(RequestHandler): """对应/""" def get(self): self.write("主页") class LoginHandler(RequestHandler): """对应/login""" def get(self): self.write('<form method="post"><input type="submit" value="登陆"></form>') def post(self): self.redirect("/") # 重定向到首页 -
send_error(status_code=500, **kwargs)
-
说明:抛出HTTP错误状态码status_code,默认为500,kwargs为可变命名参数。使用send_error抛出错误后tornado会调用write_error()方法进行处理,并返回给浏览器处理后的错误页面
-
示例
class IndexHandler(RequestHandler): def get(self): self.write("主页") self.send_error(404, content="出现404错误")注意:默认的
write_error()方法不会处理send_error抛出的kwargs参数,即上面的代码中content="出现404错误"是没有意义的继续使用write方法
class IndexHandler(RequestHandler): def get(self): self.write("主页") self.send_error(404, content="出现404错误") self.write("结束") # 我们在send_error再次向输出缓冲区写内容注意:使用send_error()方法后就不会再向输出缓冲区写内容了
-
-
write_error(status_code, **kwargs)
-
说明:用来处理send_error抛出的错误信息并返回给浏览器错误信息页面。可以重写此方法来定制自己的错误显示页面
-
示例
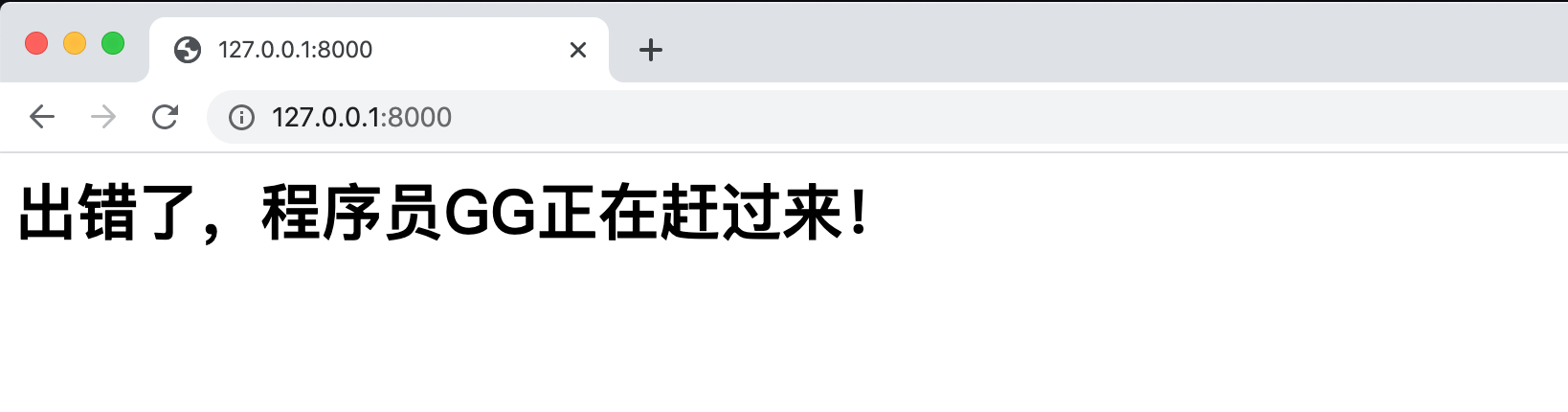
import tornado.web import tornado.ioloop from tornado.web import RequestHandler class IndexHandler(RequestHandler): def get(self): self.write("主页") self.send_error(404, content="出现404错误") self.write("结束") # 我们在send_error再次向输出缓冲区写内容 def write_error(self, status_code, **kwargs): self.write("<h1>出错了,程序员GG正在赶过来!</h1>") self.write("<p>错误名:%s</p>" % kwargs["title"]) self.write("<p>错误详情:%s</p>" % kwargs["content"]) if __name__ == "__main__": app = tornado.web.Application([ (r"/", IndexHandler), ]) app.listen(8000) tornado.ioloop.IOLoop.current().start()结果
-
四、接口与调用顺序
-
initialize()
说明:对应每个请求的处理类Handler在构造一个实例后首先执行initialize()方法
在讲输入时说过,路由映射中的第三个字典型参数会作为该方法的命名参数传递
如:
class ProfileHandler(RequestHandler): def initialize(self, database): self.database = database def get(self): ... app = Application([ (r'/user/(.*)', ProfileHandler, dict(database=database)), ])注意:此方法通常用来初始化参数(对象属性),很少使用
-
prepare()
说明:预处理,即在执行对应请求方式的HTTP方法(如get、post等)前先执行
注意:不论以何种HTTP方式请求,都会执行prepare()方法
以预处理请求体中的json数据为例:
import json class IndexHandler(RequestHandler): def prepare(self): if self.request.headers.get("Content-Type").startswith("application/json"): self.json_dict = json.loads(self.request.body) else: self.json_dict = None def post(self): if self.json_dict: for key, value in self.json_dict.items(): self.write("<h3>%s</h3><p>%s</p>" % (key, value)) def put(self): if self.json_dict: for key, value in self.json_dict.items(): self.write("<h3>%s</h3><p>%s</p>" % (key, value))用post方式发送json数据时
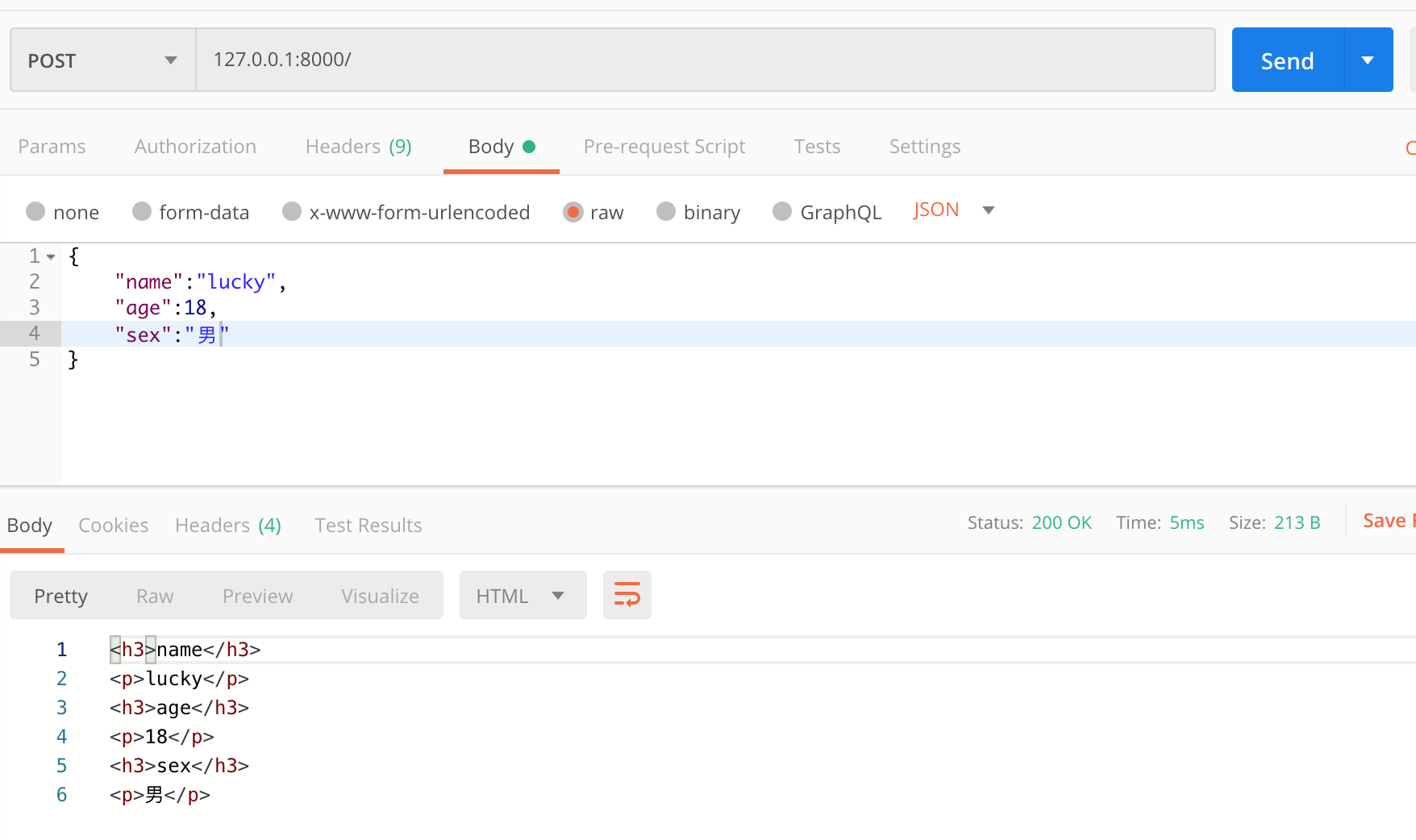
用put方式发送json数据时

- HTTP方法
| 方法 | 描述 |
|---|---|
| get | 请求指定的页面信息,并返回实体主体。 |
| head | 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| post | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| delete | 请求服务器删除指定的内容。 |
| patch | 请求修改局部数据。 |
| put | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| options | 返回给定URL支持的所有HTTP方法。 |
-
on_finish()
在请求处理结束后调用,即在调用HTTP方法后调用。通常该方法用来进行资源清理释放或处理日志等
注意:请尽量不要在此方法中进行响应输出
-
set_default_headers()
-
write_error()
-
调用顺序
示例
class IndexHandler(RequestHandler): def initialize(self): print("调用了initialize()") def prepare(self): print("调用了prepare()") def set_default_headers(self): print("调用了set_default_headers()") def write_error(self, status_code, **kwargs): print("调用了write_error()") def get(self): print("调用了get()") def post(self): print("调用了post()") self.send_error(200) # 注意此出抛出了错误 def on_finish(self): print("调用了on_finish()")

在正常情况未抛出错误时,调用顺序为:
- set_defautl_headers()
- initialize()
- prepare()
- HTTP方法
- on_finish()
在有错误抛出时,调用顺序为:
- set_default_headers()
- initialize()
- prepare()
- HTTP方法
- set_default_headers()
- write_error()
- on_finish()

微信扫描 获取更多学习资料